이 글은 Gitlab 공식 사이트의 글을 번역/편집 하여 작성 하였습니다.
참고자료: https://docs.gitlab.com/ee/administration/reference_architectures/
Gitlab Architecture 는
단일 서버에 GitLab을 설정하거나 사용자의 수가 증가 함에 따라 많은 사용자에게 서비스를 제공하도록 확장 할 수 있습니다. GitLab 품질 및 지원 팀에서 구축 및 검증한 권장한 Architecture에 대해 알아 보겠습니다.
사용자가 2,000명 미만인 GitLab 인스턴스의 경우 단일 노드에 GitLab을 설치 하여 기본 설정을 사용하여 유지 및 관리 하는 것이 리소스 비용을 최소화하는 것에 유리 합니다.
조직에 2,000명 이상의 사용자가 있는 경우 GitLab 구성 요소를 여러 노드로 확장하는 것이 좋습니다. 시스템 노드는 구성 요소별로 그룹화 됩니다. 이러한 노드를 추가하면 GitLab 인스턴스의 성능과 확장성이 향상됩니다.
Gitlab 확장 시 고려 할 점
- Frontend 트래픽을 처리하기 위한 여러 애플리케이션 노드.
- 트래픽 분산 처리를 위한 로드 밸런서.
- Storage, PostgreSQL 및 Redis 에 애플리케이션 노드 연결.
Workflow 에 따라 다음 권장 참조 아키텍처를 적절하게 조정해야 할 수 있습니다. Workload는 사용자의 활동 정도, 자동화 수준, 미러링, 저장소/변경 크기 등의 요인에 의해 영향을 받습니다.
Cloud Provider 에서 구성 시 고려할 항목
Ommnibus or Cloud Native Hybrid 형식 구성이 가능 한지 비교

Cloud Provider 별 추천 리소스

Cloud Provider 권장 하지 않는 리소스
- AWS Aurora DB : 호환성 문제로 인해 권장되지 않습니다.
- Azure Blob Storage : 특정 시간에 PROD 사용에 영향을 줄 수 있는 성능 제한이 있는 것으로 확인되었습니다.
- Azure Databases for PostgesSQL Server : 현저한 성능 문제 또는 누락된 기능으로 인해 사용하지 않는 것이 좋습니다.
Gitlab 가용성 컴포넌트
Gitlab 은 가용성을 위해 아래의 구성 요소들이 제공 됩니다.
- 자동 백업
- 트래픽 로드 밸런서
- 제로 다운타임 업데이트
- 자동화된 데이터베이스 장애 조치
- GitLab Geo를 사용한 인스턴스 수준 복제
Reference Architecture
사용자 수에 따라 권장하는 Architecture 에 대해 알아 보겠습니다.
1000 명 사용자 Architecture
최대 1,000명의 사용자에게 서비스를 제공해야 하고 엄격한 가용성 요구 사항이 없는 경우 백업 이 빈번한 단일 노드 솔루션이 많은 조직에 적합합니다.
- 지원 사용자(대략): 1,000
- 고가용성: 아니요.
- 클라우드 네이티브 하이브리드: 아니요.
- 검증 및 테스트 결과
- RPS(test requests per second rates):
- API: 20RPS
- 웹: 2RPS
- Git(Pull): 2RPS
- Git(Push): 1RPS
- RPS(test requests per second rates):
| Users | Configuration | GCP | AWS | Azure |
|---|---|---|---|---|
| Up to 500 | 4 vCPU, 3.6 GB memory | n1-highcpu-4 | c5.xlarge | F4s v2 |
| Up to 1,000 | 8 vCPU, 7.2 GB memory | n1-highcpu-8 | c5.2xlarge | F8s v2 |
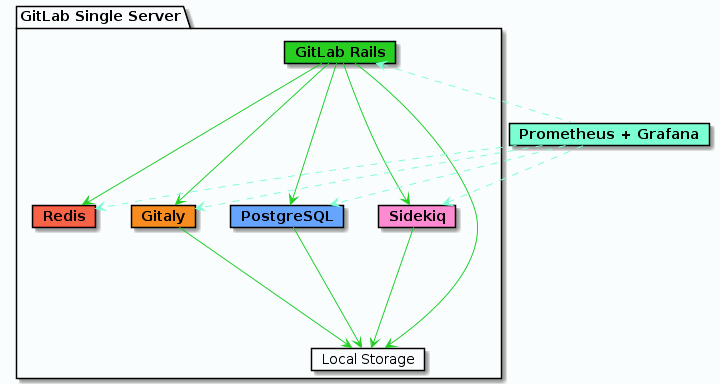
2000명 사용자 Architecture
1000명 사용자 Archtecture 에서 단일 서버에 있던 각 컴포넌트 들을 각 서버들로 분리한 아키텍쳐 입니다.
- 지원 사용자(대략): 2,000
- 고가용성: 아니요.
- 클라우드 네이티브 하이브리드: 예
- 검증 및 테스트 결과
- RPS(test requests per second rates):
- API: 40RPS
- 웹: 4RPS
- Git(Pull): 4RPS
- Git(Push): 1RPS
- RPS(test requests per second rates):
| Service | Nodes | Configuration | GCP | AWS | Azure |
|---|---|---|---|---|---|
| Load balancer3 | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| PostgreSQL1 | 1 | 2 vCPU, 7.5 GB memory | n1-standard-2 | m5.large | D2s v3 |
| Redis2 | 1 | 1 vCPU, 3.75 GB memory | n1-standard-1 | m5.large | D2s v3 |
| Gitaly | 1 | 4 vCPU, 15 GB memory | n1-standard-4 | m5.xlarge | D4s v3 |
| GitLab Rails | 2 | 8 vCPU, 7.2 GB memory | n1-highcpu-8 | c5.2xlarge | F8s v2 |
| Monitoring node | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Object storage4 | Not applicable | Not applicable | Not applicable | Not applicable | Not applicable |
| NFS server (non-Gitaly) | 1 | 4 vCPU, 3.6 GB memory | n1-highcpu-4 | c5.xlarge | F4s v2 |
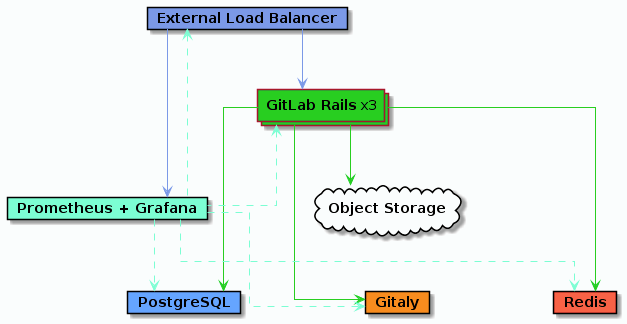
3000명 사용자 Architecture
3,000명 미만의 사용자에게 향상된 GitLab 가동 시간 및 가용성을 제공할 수 있습니다. 이 Architecture 부터 HA 구성입니다. GitLab 환경에 대해 높은 수준의 가동 시간을 유지하는 것이 요구 사항이 아니거나 이러한 종류의 환경을 유지 관리할 전문 지식이 없는 경우 GitLab 설치에 HA가 아닌 2,000명의 사용자 참조 아키텍처를 사용하는 것이 권장 합니다.
- 지원 사용자(대략): 3,000
- 고가용성: 예
- 클라우드 네이티브 하이브리드: 예
- 검증 및 테스트 결과
- RPS(test requests per second rates):
- API: 60RPS
- 웹: 6RPS
- Git(Pull): 6RPS
- Git(Push): 1RPS
- RPS(test requests per second rates):
| Service | Nodes | Configuration | GCP | AWS | Azure |
|---|---|---|---|---|---|
| External load balancing node3 | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Redis2 | 3 | 2 vCPU, 7.5 GB memory | n1-standard-2 | m5.large | D2s v3 |
| Consul1 + Sentinel2 | 3 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| PostgreSQL1 | 3 | 2 vCPU, 7.5 GB memory | n1-standard-2 | m5.large | D2s v3 |
| PgBouncer1 | 3 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Internal load balancing node3 | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Gitaly5 | 3 | 4 vCPU, 15 GB memory | n1-standard-4 | m5.xlarge | D4s v3 |
| Praefect5 | 3 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Praefect PostgreSQL1 | 1+ | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Sidekiq | 4 | 2 vCPU, 7.5 GB memory | n1-standard-2 | m5.large | D2s v3 |
| GitLab Rails | 3 | 8 vCPU, 7.2 GB memory | n1-highcpu-8 | c5.2xlarge | F8s v2 |
| Monitoring node | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Object storage4 | Not applicable | Not applicable | Not applicable | Not applicable | Not applicable |
| NFS server (non-Gitaly) | 1 | 4 vCPU, 3.6 GB memory | n1-highcpu-4 | c5.xlarge | F4s v2 |
인스턴스 구성과 관련된 모든 PaaS 솔루션의 경우 탄력적인 클라우드 아키텍처 관행에 맞게 3개의 서로 다른 A-Z 영역에 최소 3개의 노드를 구현하는 것이 좋습니다.
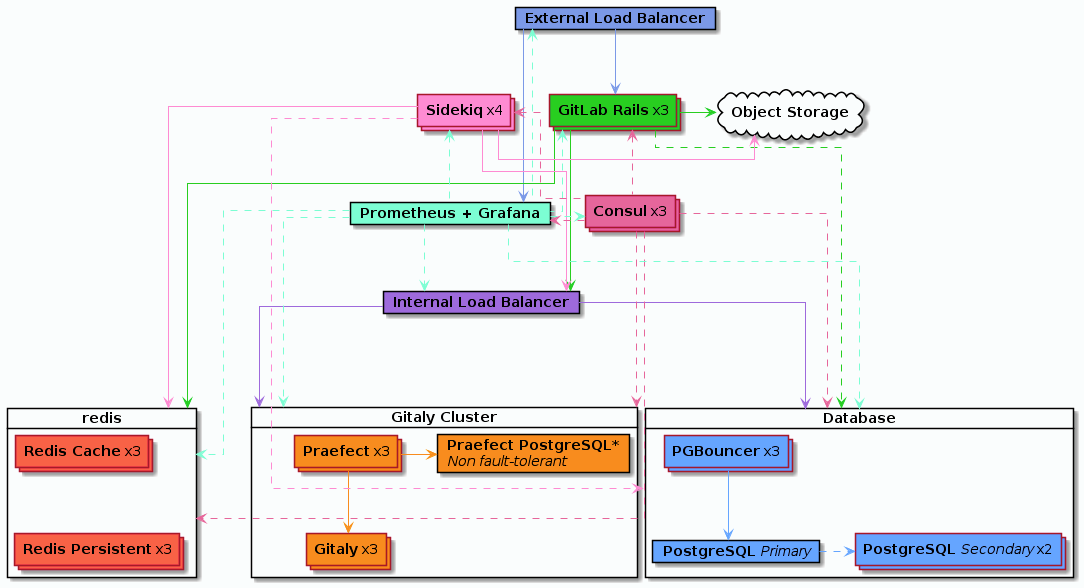
10000명 사용자 Architecture
- 지원 사용자(대략): 3,000
- 고가용성: 예
- 클라우드 네이티브 하이브리드 대안: 예
- 검증 및 테스트 결과
- RPS(test requests per second rates):
- API: 60RPS
- 웹: 6RPS
- Git(Pull): 6RPS
- Git(Push): 1RPS
- RPS(test requests per second rates):
| Service | Nodes | Configuration | GCP | AWS | Azure |
|---|---|---|---|---|---|
| External load balancing node3 | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Consul1 | 3 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| PostgreSQL1 | 3 | 8 vCPU, 30 GB memory | n1-standard-8 | m5.2xlarge | D8s v3 |
| PgBouncer1 | 3 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Internal load balancing node3 | 1 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Redis/Sentinel – Cache2 | 3 | 4 vCPU, 15 GB memory | n1-standard-4 | m5.xlarge | D4s v3 |
| Redis/Sentinel – Persistent2 | 3 | 4 vCPU, 15 GB memory | n1-standard-4 | m5.xlarge | D4s v3 |
| Gitaly5 | 3 | 16 vCPU, 60 GB memory | n1-standard-16 | m5.4xlarge | D16s v3 |
| Praefect5 | 3 | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Praefect PostgreSQL1 | 1+ | 2 vCPU, 1.8 GB memory | n1-highcpu-2 | c5.large | F2s v2 |
| Sidekiq | 4 | 4 vCPU, 15 GB memory | n1-standard-4 | m5.xlarge | D4s v3 |
| GitLab Rails | 3 | 32 vCPU, 28.8 GB memory | n1-highcpu-32 | c5.9xlarge | F32s v2 |
| Monitoring node | 1 | 4 vCPU, 3.6 GB memory | n1-highcpu-4 | c5.xlarge | F4s v2 |
| Object storage4 | Not applicable | Not applicable | Not applicable | Not applicable | Not applicable |
| NFS server (non-Gitaly) | 1 | 4 vCPU, 3.6 GB memory | n1-highcpu-4 | c5.xlarge | F4s v2 |
구성 시 주의 할 점
- 타사의 외부 PaaS PostgreSQL 솔루션을 사용 할 수 있습니다.
- Google Cloud SQL 및 Amazon RDS가 작동하는 것으로 알려져 있지만 Azure Database for PostgreSQL은 성능 문제로 인해 권장되지 않습니다.
- Consul은 주로 PostgreSQL 고 가용성을 위해 사용되므로 PostgreSQL PaaS 설정을 사용할 때 무시할 수 있습니다.
- Omnibus 자동 호스트 검색을 위해 Prometheus에서 선택적으로 사용되기도 합니다.
- 타사의 외부 PaaS Redis 솔루션을 사용 할 수 있습니다.
- Google Memorystore
- AWS ElastiCache
- 타사의 로드 밸런싱 서비스(LB PaaS)를 사용 할 수 있습니다.
- AWS ELB
- 클라우드 구현을 위해 오브젝트 스토리지(스토리지 PaaS)에서 실행해야 합니다.
- Google Cloud Storage
- AWS S3
- Gitaly Cluster는 내결함성의 이점을 제공하지만 설정 및 관리가 더 복잡합니다.
마치며..
Gitlab을 직접 구성하여 사용 할 때, 사용자 수에 따라 Architecture를 확장 하여 안정성을 높일 수 있다는 점을 알아 보았습니다. 이번 Gitlab Architecture를 알아보면서 사용자의 수에 따라 Architecture를 확장 할 수 있는 반면, 구성에 필요한 Storage, Databases, Cache Service등 컴포넌트들의 노드 개수와 성능 요구 사항이 기하급수적으로 늘어난다는 사실을 알 수 있었습니다. 확장된 인프라인 만큼 유지보수를 위한 관리자 인력 자원과 인프라 비용도 같이 늘어나게 됩니다.
안정적인 서비스를 위해 고가용성 인프라 구성에 관심이 많은 것 같습니다. 하지만 사용자 수가 2000명 이하일 경우 HA 구성을 하지 않아도 안정적인 구성이 가능 하다는 점과 HA 구성을 위해서 3000명 이상의 Architecture 를 필요로 한다는 것을 보았을 때 과연 필요한 서비스 인지 꼼꼼하게 체크 하여 상황에 맞는 Architecture를 구성 한다면 인력과 인프라 비용을 효율적으로 관리 할 수 있을 것 같습니다.
참고 사이트