

이번 글은 Amazon 공식 사이트에서 MSK 개발자 가이드 문서를 번역/편집하여 작성 하였습니다.
참고자료 : Welcome to the Amazon MSK Developer Guide – Amazon Managed Streaming for Apache Kafka
3부 에서는 Amazon MSK 의 기능인 Connect 와 Worker 에 대해 알아 보겠습니다.
MSK 커넥트란 무엇입니까?
MSK Connect는 개발자가 Apache Kafka Cluster로 데이터를 쉽게 스트리밍 할 수 있도록 해주는 Amazon MSK의 기능입니다. MSK Connect는 Apache Kafka 클러스터를 데이터베이스, 검색 인덱스 및 파일 시스템과 같은 외부 시스템과 연결하기 위한 오픈 소스 프레임워크 인 Kafka Connect 2.7.1을 사용합니다.
MSK Connect를 사용하면 Amazon S3 및 Amazon OpenSearch Service(구, Amazon ElasticSerch)와 같은 인기 있는 데이터 스토어로 데이터를 이동하거나 데이터를 가져오는 Kafka Connect용으로 구축된 완전 관리형 커넥터를 배포할 수 있습니다. 데이터베이스의 변경 로그를 Apache Kafka 클러스터로 스트리밍하기 위해 Debezium과 3rd Party 커넥터를 배포하거나 코드 변경 없이 기존 커넥터를 배포할 수 있습니다. 커넥터는 부하 변화에 맞게 자동으로 확장되며 사용한 리소스에 대해서만 비용을 지불합니다.
MSK Connect 기능
- Source Connector 를 사용하여 외부 시스템에서 Topic으로 데이터를 가져옵니다. Sink Connector 를 사용하면 Topic의 데이터를 외부 시스템으로 내보낼 수 있습니다.
- MSK Cluster 혹은 Apache Kafka Cluster 상관없이 Amazon VPC에 연결된 모든 Apache Kafka Cluster Conncet 를 지원합니다.
- Connector 상태 및 전달 상태를 지속적으로 모니터링하고, 기본 하드웨어를 패치 및 관리하고, 처리량 변화에 맞게 커넥터를 Auto Scale 합니다.
Kafka의 Connectors 란?
Connector 는 데이터 원본에서 Apache Kafka Cluster로 스트리밍 데이터를 지속적으로 복사하거나 클러스터에서 데이터 Sink 로 데이터를 지속적으로 복사하여 외부 시스템 및 Amazon 서비스를 Apache Kafka와 연결 합니다.
Connector 는 데이터를 대상에 전달하기 전에 변환, 형식 변환 또는 데이터 필터링과 같은 간단한 논리를 수행할 수도 있습니다.
Source Connector 는 Data source 에서 데이터를 가져와 Cluster 로 푸시하고, Sink Connector는 Cluster에서 데이터를 가져와 Data sink 에 푸시 합니다.

Connector 용량
Connector 의 총 용량은 Connector 에 있는 Worker 수와 Worker 당 MCU(MSK Connect Units) 수에 따라 달라집니다. 각 MCU는 컴퓨팅 vCPU 1개와 4GiB의 메모리를 나타냅니다. Connector 를 생성하려면 다음 두 가지 용량 모드 중 하나를 선택해야 합니다.
- Provisioned : Worker 수와 Worker 당 MCU 수를 지정할 수 있습니다.
- Autoscaled : Worker 수와 Worker 당 MCU 수에 비례하는 값을 자동으로 설정 하여 tasks.max 속성에 설정 합니다.
- Provisioned 와 달리 Autoscale 지표가 되는 Connector의 CPU utilization를 설정합니다.
Plugin
플러그인은 AWS커넥터 로직을 정의하는 코드를 포함하는 리소스 입니다.
JAR 파일 (또는 하나 이상의 JAR 파일이 포함된 ZIP 파일) 을 S3 버킷에 업로드하고 플러그인을 생성할 때 버킷의 위치를 지정합니다. 커넥터를 생성할 때 MSK Connect에서 사용할 플러그인을 지정합니다. 플러그인과 커넥터의 관계는 일대다 관계입니다. 동일한 플러그인에서 하나 이상의 커넥터를 생성할 수 있습니다.

Plugin 사용 Architecture 사례 (참고 사이트 : https://medium.com/@sharmaranupama/stream-data-from-yugabyte-cdc-to-aws-msk-using-debezium-a09490c54851 )
Worker
Worker 는 Connector의 논리대로 실행 하는 JVM(Java Virtual Machine) 프로세스 입니다. 각 Worker 는 병렬 스레드로 실행 되는 Task 를 만들고 데이터 복사 작업을 수행 합니다.
특징으로, Task 들은 상태를 저장하고 있지 않으므로 탄력적이고 확장 가능한 Data Pipline을 제공 하기 위해 언제든지 Stop/Start/Restart 할 수 있습니다.
스케일링 이벤트나 예상치 못한 실패로 인한 Worker 수 변경은 나머지 Worker 에 의해 자동으로 감지됩니다. 나머지 Worker 집합에서 Task 의 균형을 조정하도록 조정합니다. Connect Worker는 Apache Kafka의 Consumer group 을 사용하여 조정하고 균형을 조정합니다.
Connector 의 용량 요구 사항이 가변적이거나 추정하기 어려운 경우 MSK Connect에서 지정한 하한과 상한 사이에서 필요에 따라 작업자 수를 조정하도록 할 수 있습니다. Connector 로직을 실행할 정확한 작업자 수를 지정할 수도 있습니다. (Connector 용량 참조)
Default Worker Configuration
MSK Connect는 다음과 같은 기본 작업자 구성을 제공합니다.

Supported Worker Configuration Properties
- MSK Connect 가 지원하는 Producer 구성 속성
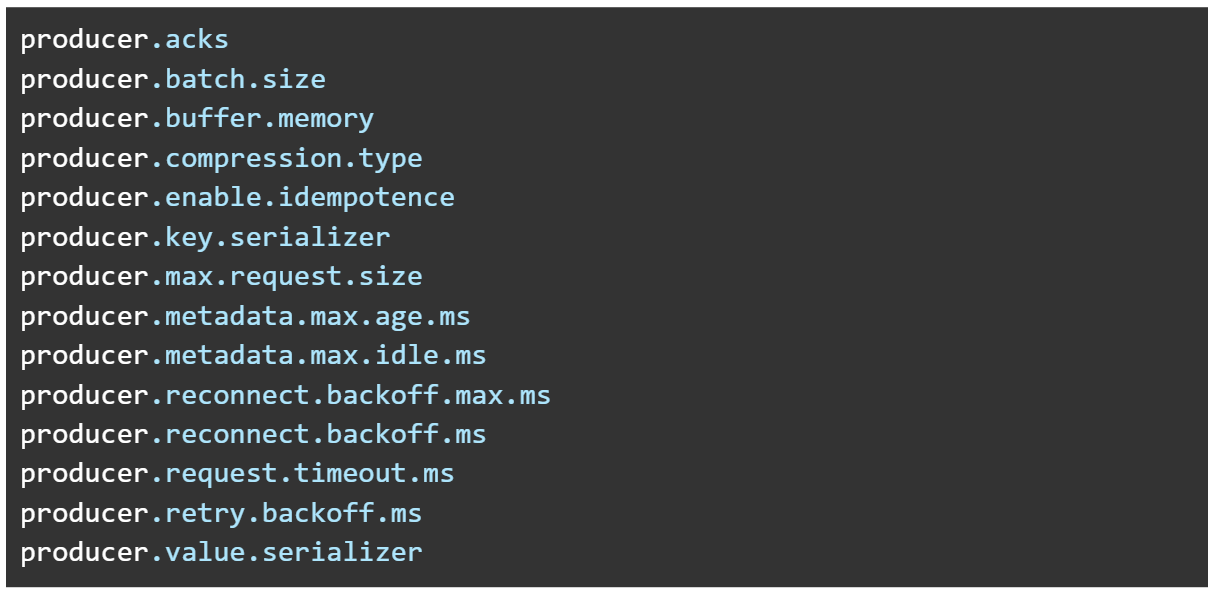
- MSK Connect 가 지원하는 Consumer 구성 속성
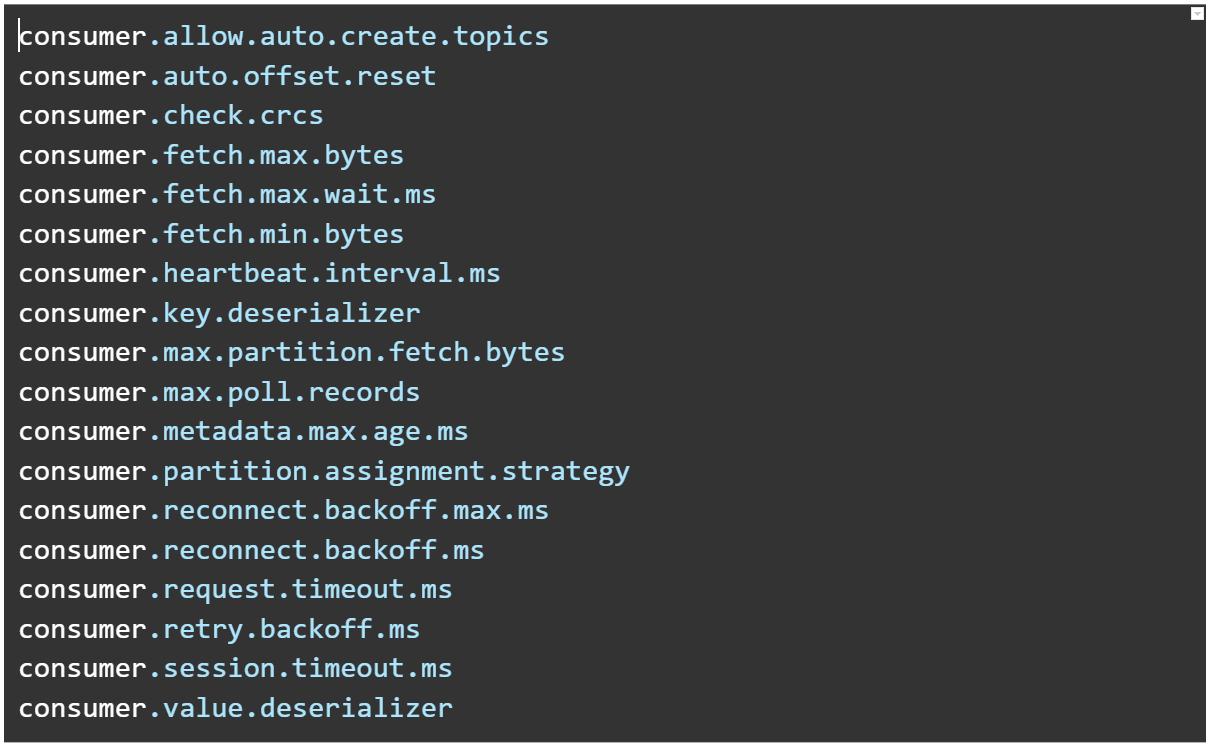
- 다음으로 시작하는 속성을 제외한 접두사를 지원

Secrets
AWS Secrets Manager와 같은 서비스를 사용하여 민감한 Configuration 값을 외부화 하려면 ConfigProvider 클래스 인터페이스를 구현하는 ConfigProvider 를 설정할 수 있습니다.
ConfigProvider 를 사용하면 Connector 또는 Worker 구성에서 일반 텍스트 대신 변수를 지정할 수 있으며 자격 증명 및 기타 Secrets 정보가 일반 텍스트로 표시 되지 않습니다. ConfigProvider plugin 은 사용자가 직접 개발할 수 있고, 3rd-Party plugin을 사용 할 수 있습니다.
직접 개발 하기 위한 가이드
- Java ServiceLoader 기능을 사용하여 검색되는 ConfigProvider 인터페이스를 구현합니다.
- ConfigProvider 구현 클래스의 정규화된 이름을 포함하는 META-INF/services/org.apache.kafka.common.config.provider.ConfigProvider 라는 파일을 만듭니다.
- 이 파일을 구현 클래스와 함께 JAR 로 패키징 합니다.
- Kafka Connect 열거형 상수 ConfigDef.Type.PASSWORD 를 사용하여 Secret 값을 정의합니다.
3부 에서는 MSK 의 Connect, Worker에 대한 기능과 Worker 개발에 필요한 구성 속성, Plugin, Secret 에 대해 알아 보았습니다. 4부에서는 MSK 안정 적인 서비스를 위한 모니터링에 대해 알아 보겠습니다.
참고 사이트
- https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect.html
- https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect-connectors.html
- https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect-plugins.html
- https://medium.com/@sharmaranupama/stream-data-from-yugabyte-cdc-to-aws-msk-using-debezium-a09490c54851
- https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect-workers.html
- https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect-config-provider.html