
이번 글은 Amazon 공식 사이트에서 MSK 개발자 가이드 문서를 번역/편집하여 작성 하였습니다.
참고자료 : Welcome to the Amazon MSK Developer Guide – Amazon Managed Streaming for Apache Kafka
4부 에서는 MSK 안정 적인 서비스를 위한 모니터링 방법에 대해 알아 보겠습니다.
MSK 모니터링
Amazon MSK 는 기본적으로 Apache Kafka 지표를 수집하고 이를 CloudWatch 로 보내주어 모니터링 할 수 있습니다. 그리고 오픈 소스인 Prometheus를 이용하여 MSK Cluster를 모니터링 할 수도 있습니다.
MSK 지표 (With CloudWatch)
DEFAULT 모니터링 수준에서 사용 가능한 지표
| 이름 | 지표 확인 시점 | 수집 대상 | 설명 |
|---|---|---|---|
| ActiveControllerCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name | 클러스터당 하나의 컨트롤러만 활성화 |
| BurstBalance | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 클러스터의 EBS 볼륨에 대한 입-출력 버스트 크레딧의 나머지 잔액(참조 I/O 크레딧 및 버스트 성능) |
| BytesInPerSec | 주제를 생성한 후 | Cluster Name, Broker ID, Topic | 클라이언트로부터 받은 초당 byte 수 |
| BytesOutPerSec | 주제를 생성한 후 | Cluster Name, Broker ID, Topic | 클라이언트에 전송된 초당 byte 수 |
| ConnectionCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 활성 아파치 카프카 연결 수 |
| CPUCreditBalance | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker의 CPU 크레딧 잔액을 모니터링 |
| CpuIdle | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | CPU 유휴 시간의 백분율 |
| CpuSystem | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 커널 공간에 있는 CPU의 백분율 |
| CpuUser | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 사용자 공간에 있는 CPU의 백분율 |
| GlobalPartitionCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name | 복제본을 제외한 클러스터의 모든 Topic에 걸쳐 있는 파티션 수 |
| GlobalTopicCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name | 클러스터의 모든 Broker에 있는 총 Topic 수 |
| EstimatedMaxTimeLag | 소비자 그룹이 주제에서 소비한 후 | Consumer group, Topic | 드레인 예상 시간 (초)MaxOffsetLag. |
| KafkaAppLogsDiskUsed | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 애플리케이션 로그에 사용된 디스크 공간의 백분율 |
| KafkaDataLogsDiskUsed(Cluster Name, Broker ID차원) | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 데이터 로그에 사용된 디스크 공간의 백분율 |
| KafkaDataLogsDiskUsed(Cluster Name차원) | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name | 데이터 로그에 사용된 디스크 공간의 백분율 |
| LeaderCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 복제본을 포함하지 않는 Broker당 파티션의 총 리더 수 |
| MaxOffsetLag | 소비자 그룹이 주제에서 소비한 후 | Consumer group, Topic | 주제의 모든 파티션에 걸친 최대 오프셋 지연 |
| MemoryBuffered | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에 대한 버퍼링된 메모리의 크기(byte) |
| MemoryCached | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에 대한 캐시 메모리의 크기(byte) |
| MemoryFree | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에 사용할 수 있는 메모리의 크기(byte) |
| HeapMemoryAfterGC | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 가비지 수집 후 사용 가능한 총 힙 메모리의 백분율 |
| MemoryUsed | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에서 사용 중인 메모리의 크기(byte) |
| MessagesInPerSec | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker의 초당 수신 메시지 수 |
| NetworkRxDropped | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 삭제된 수신 패키지의 수 |
| NetworkRxErrors | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에 대한 네트워크 수신 오류 수 |
| NetworkRxPackets | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에서 수신된 패킷 수 |
| NetworkTxDropped | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 삭제된 전송 패키지의 수 |
| NetworkTxErrors | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker의 네트워크 전송 오류 수 |
| NetworkTxPackets | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker가 전송한 패킷 수 |
| OfflinePartitionsCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name | 클러스터에서 오프라인 상태인 총 파티션 수 |
| PartitionCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 복제본을 포함하여 Broker당 총 주제 파티션 수 |
| ProduceTotalTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 밀리초 단위의 평균 생산 시간. |
| RequestBytesMean | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에 대한 요청 byte의 평균 수 |
| RequestTime | 요청 조절이 적용된 후 | Cluster Name, Broker ID | Broker 네트워크 및 I/O 스레드가 요청을 처리하는 데 소비한 평균 시간(ms) |
| RootDiskUsed | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker가 사용하는 루트 디스크의 백분율 |
| SumOffsetLag | 소비자 그룹이 주제에서 소비한 후 | Consumer group, Topic | 주제의 모든 파티션에 대한 집계된 오프셋 지연 |
| SwapFree | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에서 사용할 수 있는 스왑 메모리의 크기(byte) |
| SwapUsed | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에서 사용 중인 스왑 메모리의 크기(byte) |
| TrafficShaping | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | 네트워크 할당을 초과하여 삭제된 패킷 수 |
| UnderMinIsrPartitionCount | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker의 minIsr 파티션 수 |
| UnderReplicatedPartitions | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker에 대해 복제가 덜 진행된 파티션 수 |
| ZooKeeperRequestLatencyMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Apache 평균 지연 시간 ZooKeeper Broker의 요청. |
| ZooKeeperSessionState | 클러스터가 ACTIVE 상태에 도달한 후 | Cluster Name, Broker ID | Broker의 ZooKeeper 세션 연결 상태 값NOT_연결됨: ‘0.0’연관 작업: ‘0.1’연결: ‘0.5’연결된 읽기 전용: ‘0.8’연결됨: ‘1.0’닫힘: ‘5.0’인증_실패: ‘10.0’ |
PER_BROKER 레벨 모니터링
모니터링 레벨을 PER_BROKER로 설정하면 모든 DEFAULT 레벨 지표 외에 다음 표에 설명된 지표를 추가로 수집 합니다. 아래 표의 지표에 대해 비용을 지불 합니다. (단, Default 레벨의 지표는 무료)
PER_BROKER 모니터링 수준부터 사용할 수 있는 추가 지표
| 이름 | 지표 확인 시점 | 설명 |
|---|---|---|
| BwInAllowanceExceeded | 클러스터가 ACTIVE 상태에 도달한 후 | 인바운드 집계 대역폭이 Broker의 최대값을 초과하여 형성된 패킷 수 |
| BwOutAllowanceExceeded | 클러스터가 ACTIVE 상태에 도달한 후 | 아웃바운드 집계 대역폭이 Broker의 최대값을 초과하여 형성된 패킷 수 |
| ConnTrackAllowanceExceeded | 클러스터가 ACTIVE 상태에 도달한 후 | 연결 추적이 Broker의 최대값을 초과하여 형성된 패킷 수 |
| ConnectionCloseRate | 클러스터가 ACTIVE 상태에 도달한 후 | 리스너당 초당 닫힌 연결 수 |
| ConnectionCreationRate | 클러스터가 ACTIVE 상태에 도달한 후 | 리스너당 초당 설정된 새 연결 수 |
| CpuCreditUsage | 클러스터가 ACTIVE 상태에 도달한 후 | 이 지표는 인스턴스의 CPU 크레딧 사용량을 모니터링 |
| FetchConsumerLocalTimeMsMean | 생산자/소비자가 만들어진 이후 | 소비자 요청이 리더에서 처리되는 평균 시간(ms) |
| FetchConsumerRequestQueueTimeMsMean | 생산자/소비자가 만들어진 이후 | 소비자 요청이 요청 대기열에서 대기하는 평균 시간(ms) |
| FetchConsumerResponseQueueTimeMsMean | 생산자/소비자가 만들어진 이후 | 소비자 요청이 응답 대기열에서 대기하는 평균 시간(ms) |
| FetchConsumerResponseSendTimeMsMean | 생산자/소비자가 만들어진 이후 | 소비자가 응답을 보내는 평균 시간(ms) |
| FetchConsumerTotalTimeMsMean | 생산자/소비자가 만들어진 이후 | 소비자가 Broker에서 데이터를 가져오는 데 소요하는 평균 총 시간(ms) |
| FetchFollowerLocalTimeMsMean | 생산자/소비자가 만들어진 이후 | 팔로어 요청이 리더에서 처리되는 평균 시간(ms) |
| FetchFollowerRequestQueueTimeMsMean | 생산자/소비자가 만들어진 이후 | 팔로어 요청이 요청 대기열에서 대기하는 평균 시간(ms) |
| FetchFollowerResponseQueueTimeMsMean | 생산자/소비자가 만들어진 이후 | 팔로어 요청이 응답 대기열에서 대기하는 평균 시간(ms) |
| FetchFollowerResponseSendTimeMsMean | 생산자/소비자가 만들어진 이후 | 팔로어가 응답을 보내는 평균 시간(ms) |
| FetchFollowerTotalTimeMsMean | 생산자/소비자가 만들어진 이후 | 팔로어가 Broker에서 데이터를 가져오는 데 소비하는 평균 총 시간(ms) |
| FetchMessageConversionsPerSec | 주제를 생성한 후 | Broker의 초당 가져오기 메시지 변환 횟수 |
| FetchThrottleByteRate | 대역폭 조절이 적용된 후 | 초당 병목 현상 바이트 수 |
| FetchThrottleQueueSize | 대역폭 조절이 적용된 후 | 조절 대기열에 있는 메시지 수 |
| FetchThrottleTime | 대역폭 조절이 적용된 후 | 평균 가져오기 조절 시간(ms) |
| NetworkProcessorAvgIdlePercent | 클러스터가 ACTIVE 상태에 도달한 후 | 네트워크 프로세서가 유휴 상태인 시간의 평균 백분율 |
| PpsAllowanceExceeded | 클러스터가 ACTIVE 상태에 도달한 후 | 양방향 PPS가 Broker의 최대값을 초과하여 형성된 패킷 수 |
| ProduceLocalTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | 팔로어가 응답을 보내는 평균 시간(ms) |
| ProduceMessageConversionsPerSec | 주제를 생성한 후 | Broker의 초당 생산 메시지 변환 수 |
| ProduceMessageConversionsTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | 메시지 형식 변환에 소요된 평균 시간(ms) |
| ProduceRequestQueueTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | 요청 메시지가 대기열에 소비하는 평균 시간(ms) |
| ProduceResponseQueueTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | 응답 메시지가 대기열에서 소비하는 평균 시간(ms) |
| ProduceResponseSendTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | 응답 메시지를 보내는 데 소비한 평균 시간(ms) |
| ProduceThrottleByteRate | 대역폭 조절이 적용된 후 | 초당 병목 현상 바이트 수 |
| ProduceThrottleQueueSize | 대역폭 조절이 적용된 후 | 조절 대기열에 있는 메시지 수 |
| ProduceThrottleTime | 대역폭 조절이 적용된 후 | 평균 생산 조절 시간(ms) |
| ProduceTotalTimeMsMean | 클러스터가 ACTIVE 상태에 도달한 후 | 밀리초 단위의 평균 생산 시간. |
| ReplicationBytesInPerSec | 주제를 생성한 후 | 다른 Broker로부터 받은 초당 바이트 수 |
| ReplicationBytesOutPerSec | 주제를 생성한 후 | 다른 Broker에 전송된 초당 바이트 수 |
| RequestExemptFromThrottleTime | 요청 조절이 적용된 후 | Broker 네트워크 및 I/O 스레드가 조절에서 제외된 요청을 처리하는 데 소비한 평균 시간(ms) |
| RequestHandlerAvgIdlePercent | 클러스터가 ACTIVE 상태에 도달한 후 | 요청 핸들러 스레드가 유휴 상태인 시간의 평균 백분율 |
| RequestThrottleQueueSize | 요청 조절이 적용된 후 | 조절 대기열에 있는 메시지 수 |
| RequestThrottleTime | 요청 조절이 적용된 후 | 평균 요청 조절 시간(ms) |
| TcpConnections | 클러스터가 ACTIVE 상태에 도달한 후 | SYN 플래그가 설정된 수신 및 나가는 TCP 세그먼트 수를 표시 |
| TrafficBytes | 클러스터가 ACTIVE 상태에 도달한 후 | 클라이언트 (생산자 및 소비자) 와 Broker 간의 네트워크 트래픽을 전체 바이트로 표시 |
| VolumeQueueLength | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 기간 동안 완료 대기 중인 읽기 및 쓰기 작업 요청 수 |
| VolumeReadBytes | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 시간 동안 읽은 바이트 수 |
| VolumeReadOps | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 기간의 읽기 작업 수 |
| VolumeTotalReadTime | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 기간 동안 완료된 모든 읽기 작업에서 사용한 총 시간(s) |
| VolumeTotalWriteTime | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 기간 동안 완료된 모든 쓰기 작업에서 사용한 총 시간(s) |
| VolumeWriteBytes | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 기간에 기록된 바이트 수 |
| VolumeWriteOps | 클러스터가 ACTIVE 상태에 도달한 후 | 지정된 기간의 쓰기 작업 수 |
PER_TOPIC_PER_BROKER 레벨 모니터링
모니터링 레벨을 PER_TOPIC_PER_BROKER 로 설정하면 모든 PER_BROKER 및 모든 DEFAULT 레벨 지표 외에 다음 표에 설명된 지표를 추가로 수집 합니다. 아래 표의 지표에 대해 비용을 지불 합니다. (단, Default 레벨의 지표는 무료)
중요
Apache Kafka 2.4.1 이상 버전을 사용하는 Amazon MSK Cluster의 경우 다음 표의 지표는 해당 값이 처음으로 0이 아닌 값이 된 후에만 나타납니다.
PER_TOPIC_PER_BROKER 모니터링 수준부터 사용할 수 있는 추가 지표
| 이름 | 지표 확인 시점 | 설명 |
|---|---|---|
| FetchMessageConversionsPerSec | 주제를 생성한 후 | 초당 가져와서 변환한 메시지 수 |
| MessagesInPerSec | 주제를 생성한 후 | 초당 수신된 메시지 수 |
| ProduceMessageConversionsPerSec | 주제를 생성한 후 | 생산된 메시지의 초당 변환 수 |
PER_TOPIC_PER_PARTITION 레벨 모니터링
모니터링 레벨을 PER_TOPIC_PER_PARTITION 설정한 경우 모든 PER_TOPIC_PER_BROKER 지표 외에 다음 표에 설명된 지표를 추가로 수집 합니다. 아래 표의 지표에 대해 비용을 지불 합니다. (단, Default 레벨의 지표는 무료)
PER_TOPIC_PER_PARTITION 모니터링 수준부터 사용할 수 있는 추가 지표
| 이름 | 지표 확인 시점 | 설명 |
|---|---|---|
| EstimatedTimeLag | 소비자 그룹이 주제에서 소비한 후 | 오프셋 Lag을 배출하는 시간(s) |
| OffsetLag | 소비자 그룹이 주제에서 소비한 후 | 오프셋 수의 파티션 레벨 Consumer Lag 수 |
Prometheus 모니터링
- Prometheus 를 사용하여 MSK Cluster를 모니터링 할 수 있습니다. Prometheus의 remote 쓰기 기능을 사용하여 이 데이터를 Prometheus용 Amazon Managed Service에 게시 할 수 있습니다.
- Datadog, Lenses, New Relic 및 Sumo Logic 과 같이 Prometheus 형식의 지표와 호환되는 Tool 또는 Amazon MSK Open Monitoring과 통합되는 Tool을 사용할 수도 있습니다.
- Open 모니터링은 무료로 사용할 수 있지만 A-Z영역 간에 데이터를 전송하는 경우 네트워크 비용이 부과됩니다.
Open Monitoring – Prometheus 구성
사전에 MSK cluster 가 구축 되어있어야 합니다.
(선택 사항) 1단계 – 기존 클러스터에서 개방형 모니터링 활성화
개방형 모니터링을 사용하기 위해 활성화가 필요합니다. 모든 Cluster는 기본적으로 비활성화 되어 있습니다.
- 모니터링하려는 Amazon MSK 클러스터가 있는 계정에 로그인합니다.
- Amazon MSK 클러스터 콘솔 열기
- 모니터링을 활성화하려는 Amazon MSK 클러스터를 클릭합니다.
- 모니터링 섹션 으로 스크롤
- Open Monitoring을 이미 활성화한 경우 다음과 유사한 화면이 표시 됩니다. (2단계를 진행합니다)
- Open Monitoring을 활성화하지 않은 경우 다음과 유사한 화면이 표시됩니다.
- 개방형 모니터링 활성화
- 모니터링 헤더 오른쪽에 있는 ‘편집’ 버튼을 클릭합니다.
- Enable open monitoring with Prometheus확인란 선택
- JMX Exporter및 Node Exporter확인란 을 선택합니다 .
- 딸깍 하는 소리Save Changes
- 이렇게 하면 클러스터에 대한 구성 업데이트가 트리거 되며 적용하는 데 몇 분 정도 걸립니다. 아래와 같이 녹색 바가 가득 채워 지면 완료 입니다.



2단계 – 모니터링 액세스를 허용하는 보안 그룹 규칙 생성
- MSK_Monitoring규칙 없이 호출되는 새 SG 만들기
- EC2 서비스를 연 다음 Security Groups왼쪽 탐색 창에서 선택
- Create Security Group화면 상단에서 클릭
- 이름을 입력하세요 (예: MSK_Monitoring)
- 설명을 입력하세요. (예: Access to MSK monitoring from monitoring services)
- Amazon MSK Cluster가 있는 VPC 선택
- Create 클릭
- 예시:
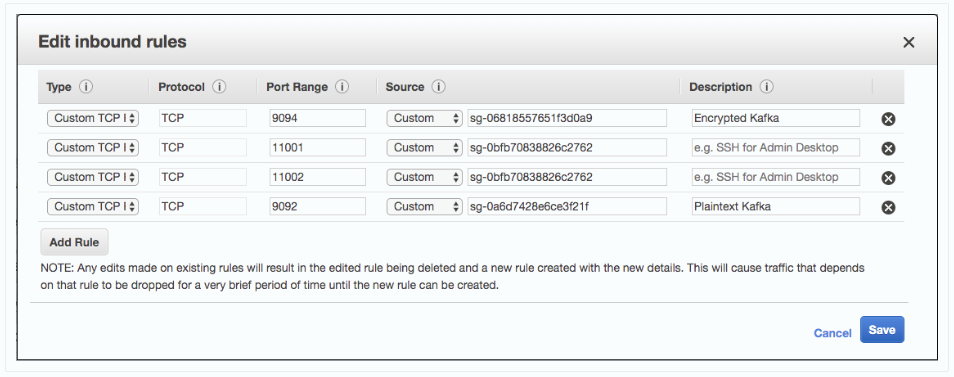
- SG(MSK Workshop Service) 에 2개의 새로운 규칙을 추가 합니다.
- EC2 서비스를 연 다음 보안 그룹으로 이동합니다.
- MSKWorkshop-KafkaService 아래에서 Edit 클릭 하고 다음 규칙을 추가 합니다.
- Type: Custom TCP
- Port range: 11001-11002
- Source: MSK_Monitoring security group
- Description: Prometheus monitoring
- 예시:
- MSK_Monitoring SG를 KafkaClientInstance 인스턴스 및 Cloud9 인스턴스에 연결합니다.
- EC2 콘솔을 열고 인스턴스로 이동합니다.
- KafkaClientInstance 호스트 선택
- 상단 바에서 Actions 선택
- Security > Change Security Groups 클릭
- MSK_Monitoring보안 그룹을 검색하여 선택 하고Add security group
- 오른쪽 하단에 있는 Save 클릭
- Cloud9 인스턴스에 대해 동일한 작업을 수행합니다.

3단계 – Run Prometheus using Docker
간단하게 구축해보기 위해 Docker를 이용합니다.
- Cloud9을 사용하여 셸 열기
- 이 실습의 대부분은 Cloud9 Bash 창에서 작업하게 됩니다. 일반 bash 환경이지만 누락된 것을 사용하려면 도구를 수동으로 설치해야 할 수도 있습니다.
- prometheus 디렉토리를 생성 합니다.

- 서비스 구성 파일 생성
프로메테우스 서버 구성 생성 :
~/prometheus/prometheus.yml

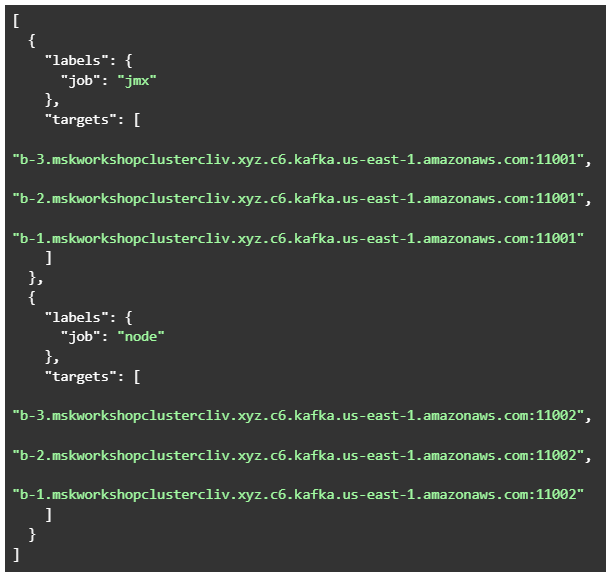
- Json 파일을 생성 합니다 : ~/prometheus/targets.json (broker_dns_[1,2,N] 부분을 수정합니다)

예시
- Prometheus 를 실행 합니다.
- 컨테이너를 풀다운하고 실행하여 위에서 만든 구성 파일을 컨테이너에 올리고 포트 9090를 사용합니다.
sudo docker run -d -p 9090:9090 –name=prometheus -v /home/ec2-user/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -v /home/ec2-user/prometheus/targets.json:/etc/prometheus/targets.json prom/prometheus –config.file=/etc/prometheus/prometheus.yml - 완료 되면 컨테이너 ID를 반환합니다. (예시)
db5fa73d5a197935cd7294b1db5b3a4d9057afe0ff2624514d28787fb3f778e6
- 컨테이너를 풀다운하고 실행하여 위에서 만든 구성 파일을 컨테이너에 올리고 포트 9090를 사용합니다.
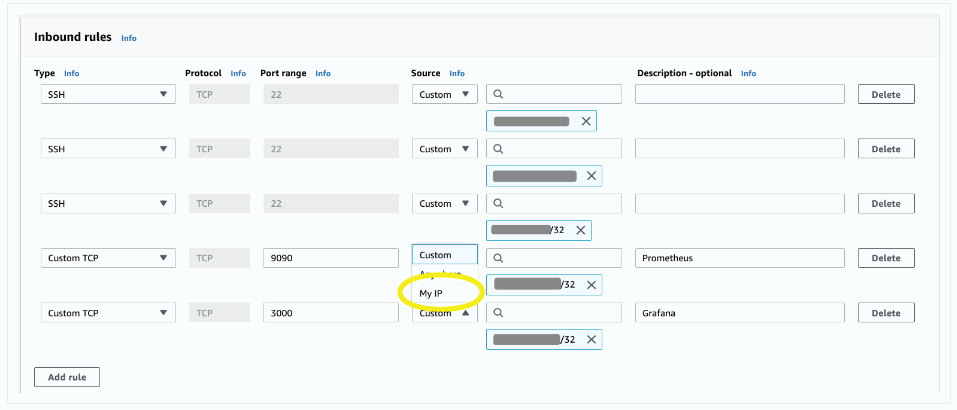
- Cloud9 인스턴스의 SG를 업데이트 합니다.
- Rule 1 – Prometheus
- Type: Custom TCP
- Port Range: 9090
- Source: MyIP, Cloud9 SG id
- Description: Prometheus
- Rule 2 – Grafana
- Type: Custom TCP
- Port Range: 3000
- Source: MyIP
- Description: Grafana
- 예시
- Rule 1 – Prometheus
4단계 – Prometheus 연결
- 콘솔에서 EC2 서비스로 전환하고 “aws-cloud9-msklab…” 인스턴스를 클릭한 다음 아래 창에서 IPv4 퍼블릭 IP 주소를 복사합니다.
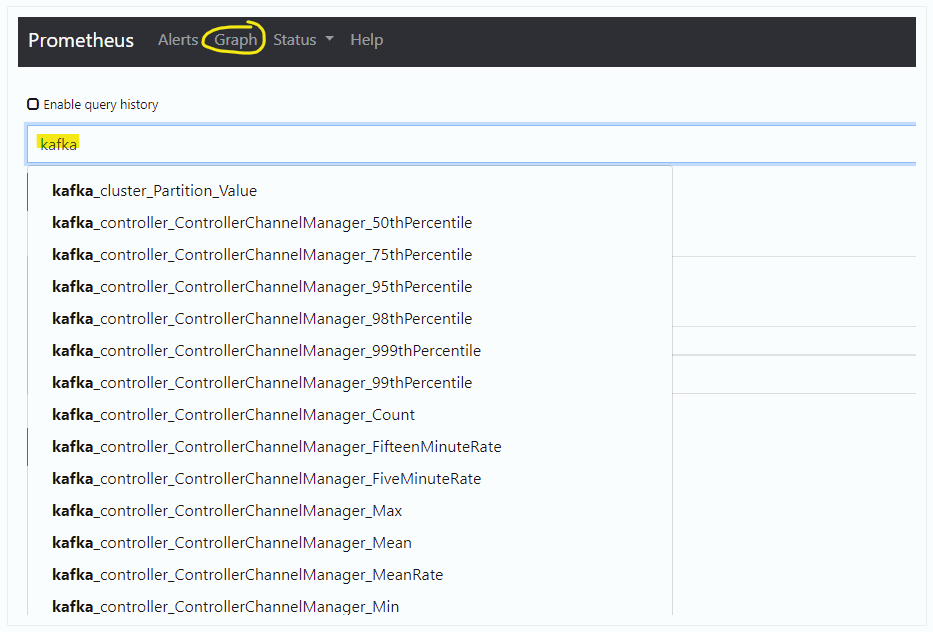
- 웹 브라우져에서 http://IP:9090 으로 접속 합니다.
- Prometheus WEB 에서 kafka 로 검색하면 지표를 확인 할 수 있습니다.

4부 에서는 Amazon MSK 모니터링을 위한 4가지 설정의 CloudWatch 지표와 Open Monitoring 을 이용해 Prometheus 를 연결 하여 보았습니다.
기본으로 제공하는 지표를 제외한 PER_BROKER, PER_TOPIC_PER_BROKER, PER_TOPIC_PER_PARTITION 설정에서는 비용이 추가 되니 꼭 필요한 상황에서만 설정해서 사용 하시길 바랍니다.
Amazon MSK 서비스를 알아보면서…
Amazon 에서 제공하는 Apache Kafka 서비스는 AWS 의 방향성에 맞는 애플리케이션 코드 개발에 더욱 힘을 쓸 수 있도록 인프라 유지보수, 서비스 확장성 등 관리적인 측면에서 많은 항목을 매니지먼트 해주는 서비스 였습니다. 데이터 메세지를 실시간으로 스트림 해야 하는 Kafka를 꼭 사용해야 하는 Architecture 에서 구축 담당자나 운영 담당자가 없는 경우 매우 쉽고 편리하게 사용하면 좋을 것 같습니다.
참고 사이트
- https://docs.aws.amazon.com/msk/latest/developerguide/metrics-details.html
- https://docs.aws.amazon.com/msk/latest/developerguide/open-monitoring.html
- https://catalog.us-east-1.prod.workshops.aws/workshops/c2b72b6f-666b-4596-b8bc-bafa5dcca741/en-US/openmonitoring